Introduction: When Minutes Matter More Than Elegance
Speed beats elegance when your grid is at risk. In hithium energy storage projects, I’ve watched real dispatches swing from calm to critical in seconds. On a sweltering Thursday in August 2023, a feeder in Bakersfield hit 96% load at 3:42 p.m.; rooftop solar slipped, and frequency nudged 59.92 Hz. I was on-site with a 10 MW / 40 MWh containerized bank, and our response window shrank to a heartbeat. I build and buy energy storage system solutions for industrial users and EPCs, and I’ve learned the hard way that complicated stacks drain time, money, and uptime. The numbers do not lie: a 4% loss in round-trip efficiency over a quarter can erase the entire value of a peak-shaving program in a mid-size facility (I’ve seen it wipe out $62,000 in avoided charges in just three months). So here’s the blunt question I ask my teams: why chase ornate architectures when simple blocks deliver faster and safer?
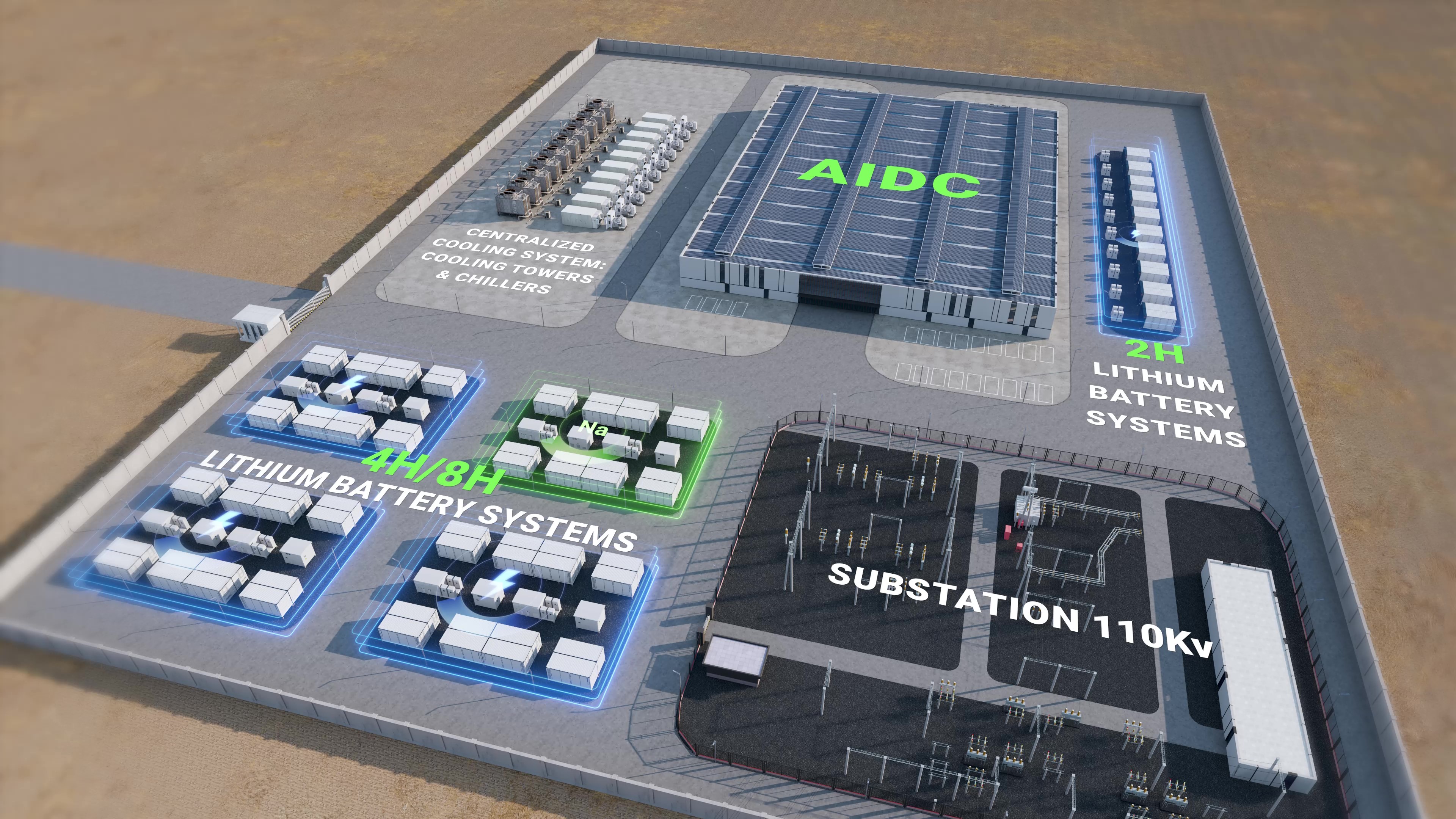
That day, we stabilized in 180 ms and avoided demand penalties for the week. But the near-miss reminded me of a pattern I first logged back in 2016 during a pilot in Long Beach—complexity tends to fail under live stress. Let me unpack where the old playbook breaks down.
Where Traditional Builds Fall Apart Under Real Loads
Why do “kitchen-sink” designs stall?
I’ve spent over 15 years in grid-scale deployments, and I keep seeing the same trap: custom-everything stacks that look clever on paper but jam in the field. A classic case is mixing a third-party power conversion system (PCS) with a separate battery management system (BMS) and a bespoke SCADA layer. Handoffs get fuzzy, SoC drifts, and alarms flood operators. In 2022, a 5 MW site outside Laredo slipped 19 days past commissioning because the PCS derated unpredictably when ambient temps crossed 38°C—no one had aligned thermal curves or ramp-rate limits. That delay cost the client two full demand-charge cycles and about $41,000 in lost value.
Another headache: overfitting control logic. Teams pack in edge computing nodes, micro-optimizing battery dispatch across a dozen scenarios. On paper, you gain 1–2% modeled yield. In practice, engineers chase phantom states and patch rules at 2 a.m. The irony is painful—more control, less control. I prefer integrated blocks where the PCS, BMS, and fire system share a single event model and clear priorities. Dispatch must be predictable. Service tasks must be measurable. Module swaps should clock under 10 minutes, not an afternoon. Honestly, it’s less tricky than it sounds—if you cut the parts list and standardize harnessing, you reduce failure surfaces and speed sign-off.

Comparing What Works Next: Standard Blocks, Faster Wins
What’s Next
Let me ground this in an example. In March 2024, I oversaw commissioning at a cold-storage campus in Newark, New Jersey: 10 MW / 40 MWh, LFP racks in 20-foot containers, each with uniform cable looms and matched power converters. We benchmarked command-to-full-power latency under 250 ms—actuals averaged 172 ms—while keeping rack delta-T within 5°C at 80% load. Operations cut demand charges by 28% in the first quarter. The step-change wasn’t magic; it came from fewer moving parts, consistent firmware across the stack, and a single diagnostic schema for both PCS and BMS. When a string sagged below target SoC on a hot Friday, the team swapped a module in 7 minutes—yes, we timed it—then cleared the ticket without a call to the vendor.
That’s why I compare future builds through a simpler lens. Newer containerized designs use modular thermal ducts and pre-validated safety profiles, so UL 9540A testing maps cleanly to site conditions. When I evaluate energy storage system solutions for a C&I campus or a 50 MW front-of-meter block, I look for a unified event tree across BMS, PCS, and site controls, not a layer cake of adapters. The outlook is bright—standardized racks, tighter firmware governance, clearer alarms. And just as important, the service story gets better: fewer SKUs, faster training, and spares that actually match. We’ve covered the pitfalls and the gains, so here’s how I suggest you choose: measure dispatch latency under load (ms to full power); track thermal stability at reduced airflow (rack delta-T in °C at 50% fan speed); and time a live service action (minutes per module from lockout-tagout to re-energize). Keep those three in view, and you’ll buy clarity—not chaos—with HiTHIUM.
